← All projects
Go to repo
Nearest Neighbor Bucket Map
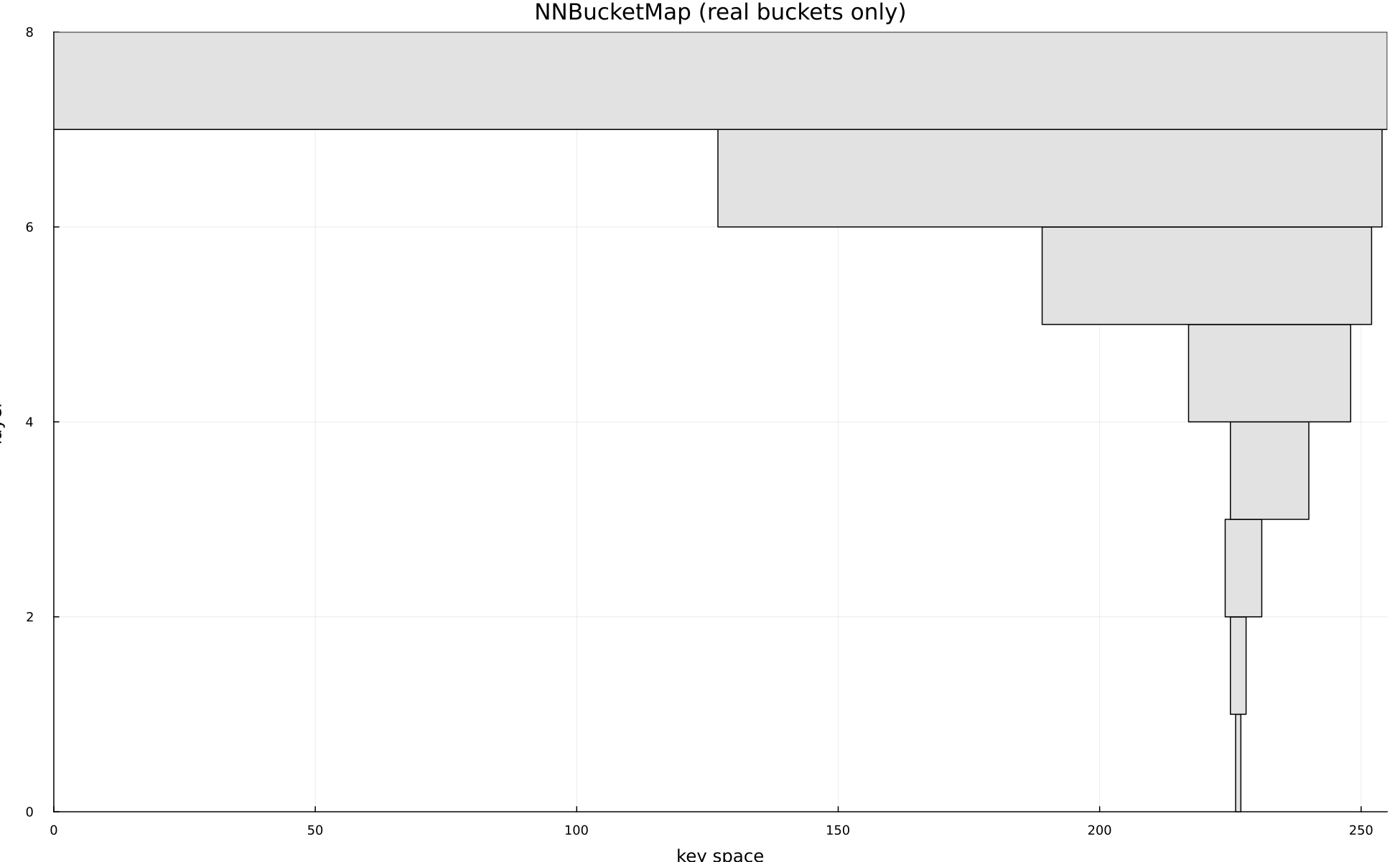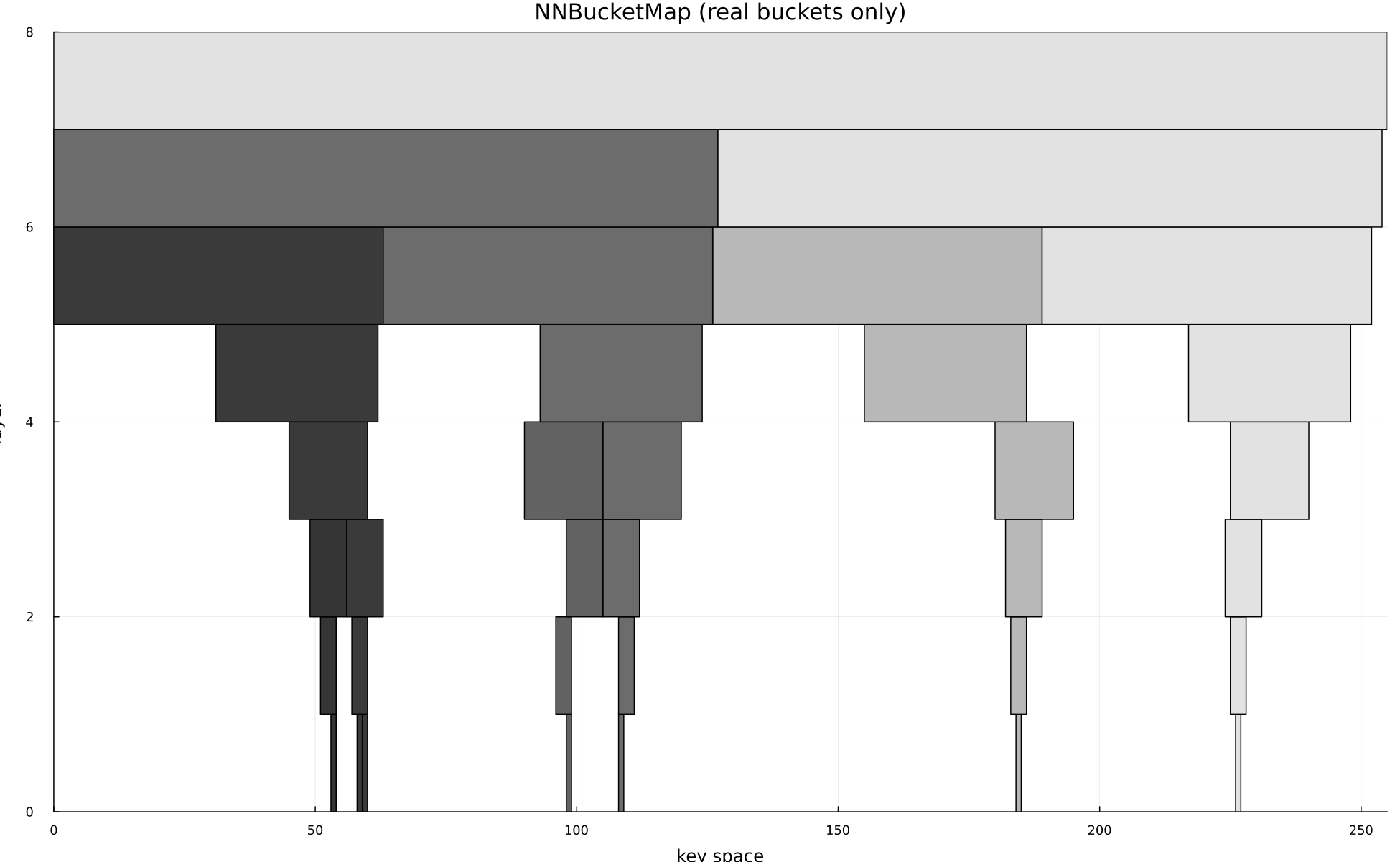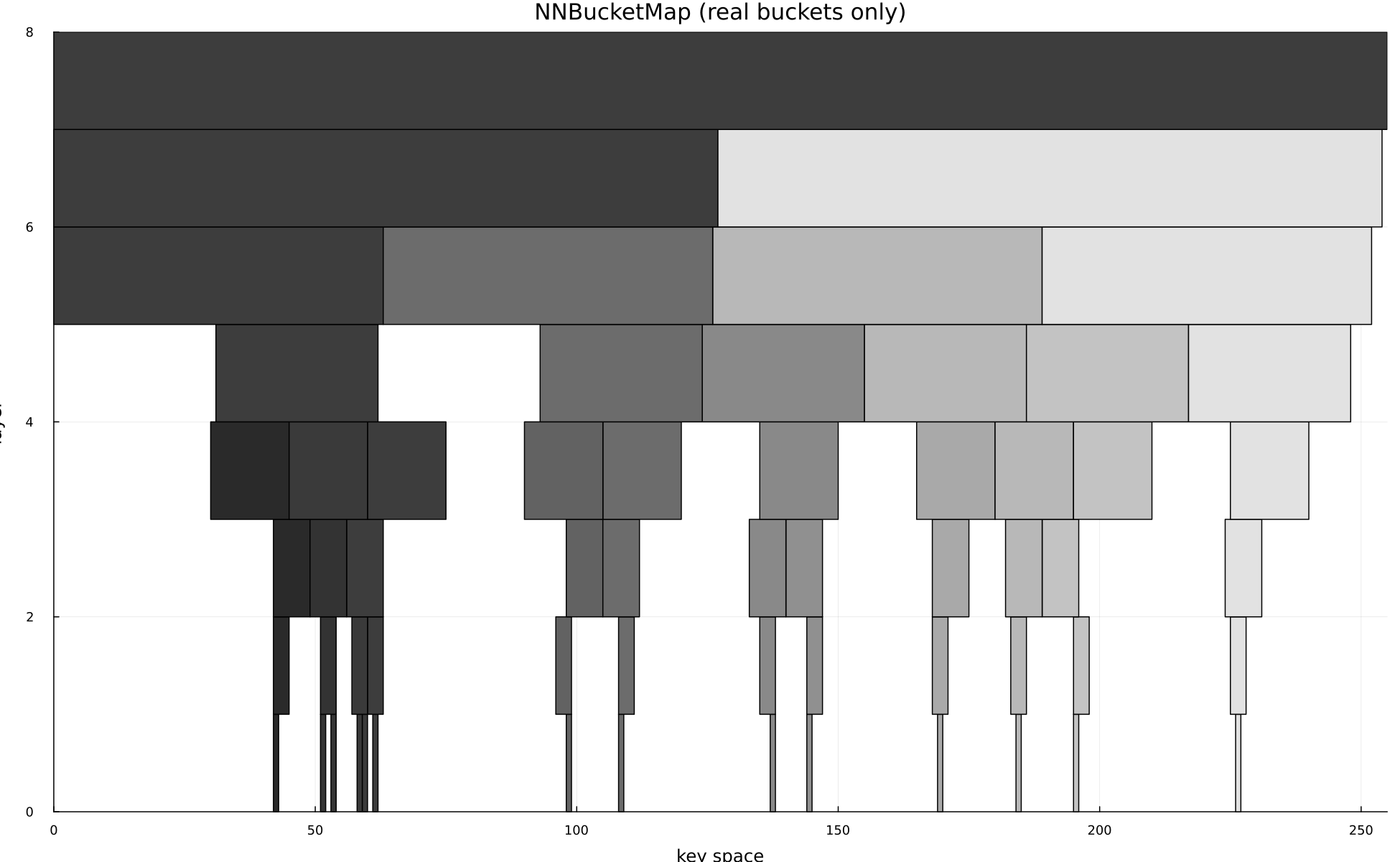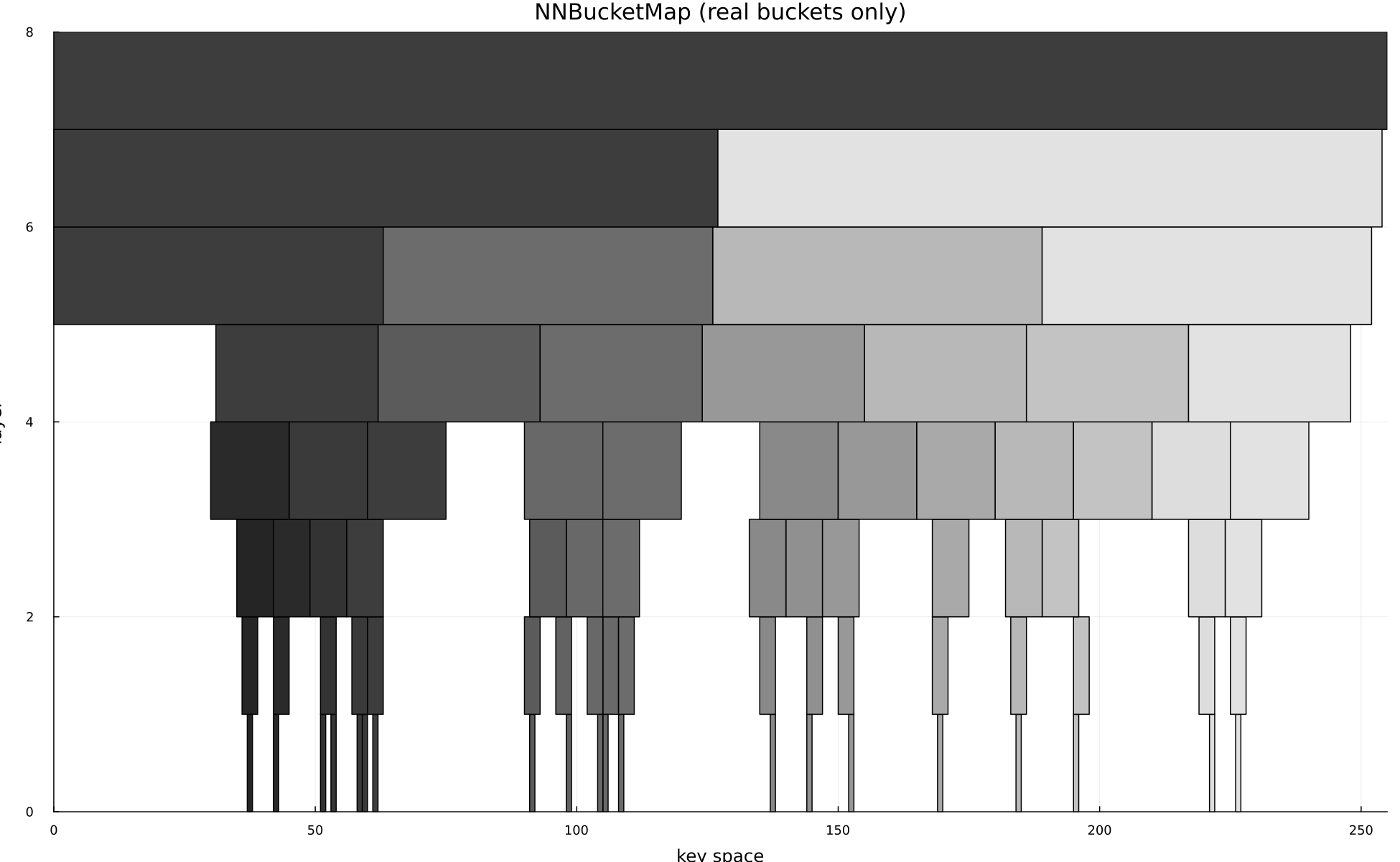
A data structure designed to get a near neighbor given some key that doesn't exist in the structure. It utilizes a logarithmically sized stack of bucket maps.
Technical case study
Problem
Given a set of named RGB colors and an arbitrary RGB value, find the nearest named color efficiently. The underlying goal was to generalize this into a practical nearest-neighbor data structure.
Next step
Generalize the structure to support non-integer numeric inputs.
Approach
- 1 Stack hash maps whose bucket sizes increase exponentially, keyed by integers or tuples of integers.
- 2 When inserting a point, place it into a bucket at each level, allowing candidate values to collide into progressively coarser buckets.
- 3 Begin a lookup at the most accurate level and climb until a populated bucket is found, then linearly scan that small candidate set for the nearest value.
- 4 For k-nearest queries, inspect adjacent buckets and linearly scan the additional candidate values.
Results
- Validated against a named-color lookup experiment containing roughly 17,000 colors.
- The repository benchmarks a median lookup around 109.67 ns, compared with roughly 2.696 ms for the linear comparison used in the experiment.
No README found for this project.